ChatGPT Images 2.0
Vom Bildgenerator zum Designhelfer

Kurz vor Redaktionsschluss bleibt in der KI-BUZZER-Redaktion meistens wenig Zeit für Spielereien. Überall offene Layouts, letzte Korrekturen, halbfertige Bildideen und mittendrin Dr. Buzz, unser KI-Maskottchen mit der türkisfarbenen Krawatte. Mal wieder als Versuchskaninchen für Bildtools.
Der Release des neuen ChatGPT-Bildmodells kam für uns genau zur richtigen Zeit: Viele Motive für die aktuelle Ausgabe waren ohnehin noch in Arbeit, also haben wir einige direkt mit ChatGPT Images 2.0 neu getestet.
Einer dieser Tests war besonders spannend. Ich gab ChatGPT drei Fotos: eines vom Chefredakteur, eines von mir und eines von Dr. Buzz. Der Auftrag war bewusst knapp: Mach daraus einen Comic auf einer A4-Seite. Sechs Panels. Wir drei diskutieren über unser Heftthema „Schöne neue KI-Welt?“, also KI zwischen Utopie und Chaos, mit Augenzwinkern. Geh dabei auch auf Inhalte aus dem Heft ein.
Mehr habe ich nicht gesagt.
Dann passierte optisch erst einmal wenig. Oben lief ein kleiner Text mit, und ich konnte sehen, wie ChatGPT sortierte, plante, prüfte. Erst danach entstand das Bild.
Der Prozess fühlte sich anders an als sonst: weniger wie „Prompt rein, Bild raus“, mehr wie ein kurzer gemeinsamer Denkprozess vor dem Entwurf.

Das fertige Bild war erstaunlich gut: sechs Panels, wiedererkennbare Figuren, lesbare Sprechblasen und kleine Redaktionsdetails im Hintergrund. Whiteboard, Heftcover, Notizen, Diskussionen über unser Thema. Spannend war vor allem, dass ich die Dialoge nicht einzeln vorgegeben hatte. ChatGPT leitete sie aus dem laufenden Kontext ab, aus unseren Heftthemen, früheren Gesprächen und den Fragen, die uns gerade beschäftigen.
Natürlich muss man so ein Ergebnis kritisch anschauen. Manches ist zu glatt, manches etwas zu viel, manches würde man redaktionell noch nachschärfen. Aber als erster visueller Entwurf war es erstaunlich nah dran.
Und damit sind wir bei der eigentlichen Neuerung.
Nicht nur bessere Bilder, sondern ein anderer Prozess
OpenAI hat ChatGPT Images 2.0 am 21. April 2026 vorgestellt. Das neue Modell soll Texte in Bildern besser darstellen, mehrere Sprachen zuverlässiger beherrschen und komplexe visuelle Aufgaben sauberer umsetzen. Der eigentliche Unterschied zeigt sich aber bei „Images with Thinking“: Bei bezahlten ChatGPT-Plänen plant das Modell vor der Bildgenerierung einen Moment länger, statt sofort loszurendern.
Ob man das wirklich „Denken“ nennen will oder nicht: In der Praxis fühlt es sich anders an. Gerade bei komplexen Aufgaben sortiert ChatGPT zuerst. Wo sitzt welcher Text? Welche Figur gehört in welches Panel? Welche Informationen sind wichtig, welche wären zu viel?
Genau dieser Schritt macht einen Unterschied. Viele Fehler bei Bild-KI entstehen nicht, weil das Modell schlecht „zeichnet“, sondern weil Aufgaben unklar sind oder Text, Bild, Layout und Kontext gleichzeitig kontrolliert werden müssen. Wenn ChatGPT vorher strukturiert, entsteht häufiger ein Bild, das nicht nur gut aussieht, sondern auch logisch funktioniert.
Nano Banana hat die Messlatte höher gelegt
Bevor ChatGPT Images 2.0 auftauchte, hatte Googles Nano Banana Pro die Erwartungen an Bild-KI bereits ordentlich verschoben. Texte wurden lesbarer, Infografiken und Mockups brauchbarer, Bildbearbeitung kontrollierter. Kleidung ändern, Frisuren anpassen, Hintergründe austauschen, Figuren über mehrere Varianten hinweg ähnlich halten: All das funktionierte plötzlich deutlich besser.
Damit rückte Bild-KI näher an echte Gestaltung heran. Nicht nur hübsche Motive, sondern nutzbare Entwürfe. Nicht perfekt, aber oft erstaunlich brauchbar.
ChatGPT Images 2.0 knüpft genau daran an, bringt aber einen eigenen Vorteil mit: Die Bildgenerierung sitzt direkt im Gespräch. Du kannst ein Thema entwickeln, über eine Idee sprechen, Korrekturen formulieren und dann sagen: „Mach daraus mal ein Bild.“ Ohne jedes Mal wieder bei null anzufangen.
Text im Bild: endlich nicht mehr nur Glücksspiel
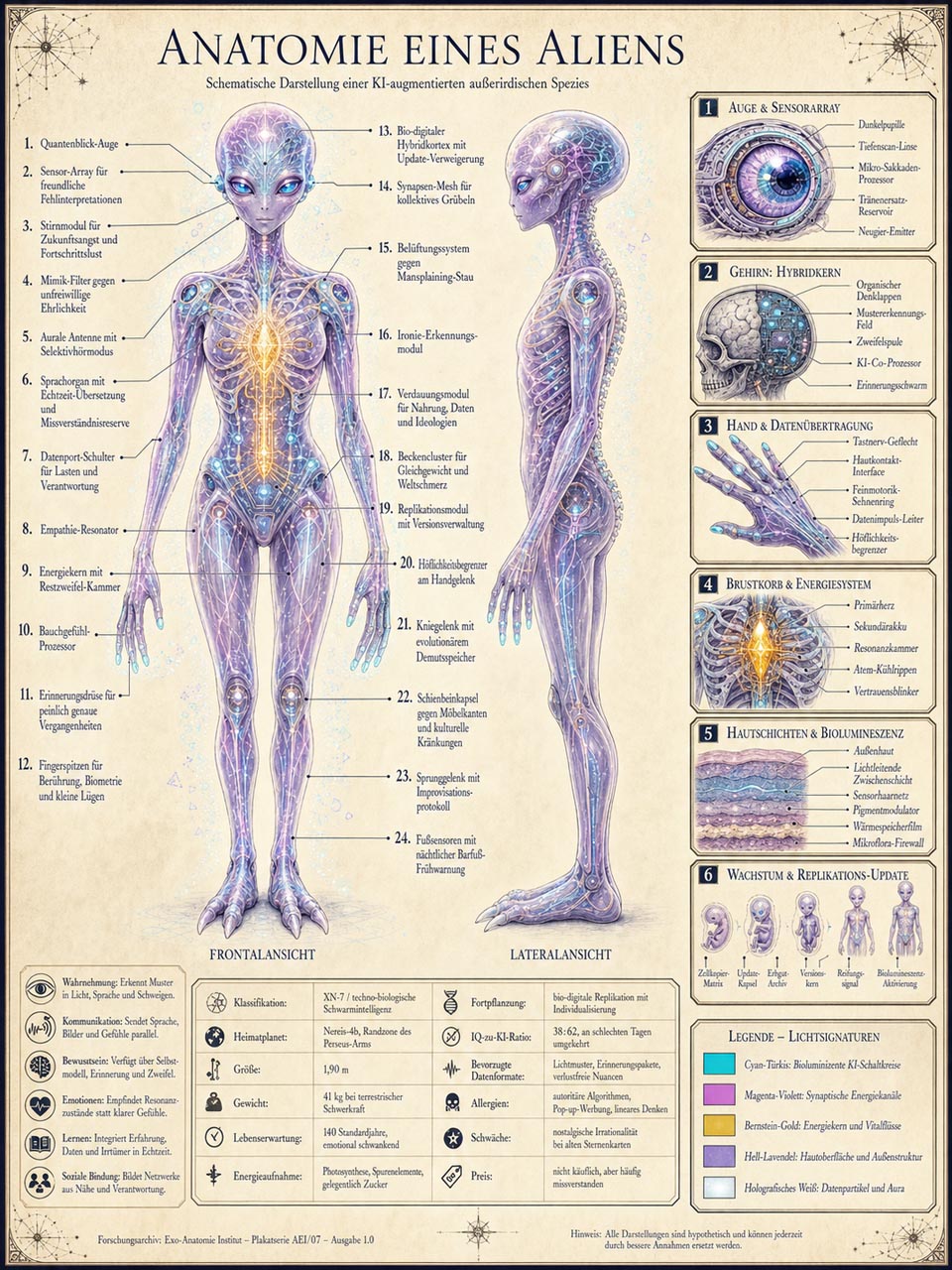
Ein Plakat zur Anatomie eines Aliens: zwei Körperansichten, 24 nummerierte Beschriftungen, mehrere Detailboxen, eine kleine Tabelle, eine Legende. Alles auf einer Fläche, alles mit relativ kleinteiligem Text und trotzdem erstaunlich klar lesbar.
Vor nicht allzu langer Zeit wäre so etwas vor allem eins gewesen: ein typografisches Trümmerfeld. Heute wirkt es auf den ersten Blick erstaunlich sauber. Noch nicht als finale Druckdatei, aber als Konzept, Entwurf oder Online-Grafik schon sehr nah an etwas, mit dem man weiterarbeiten kann.
Genau das ist für redaktionelle Arbeit spannend: Infografiken müssen nicht mehr komplett aus dem Nichts entstehen. ChatGPT liefert eine erste Struktur, die man prüfen, kürzen, korrigieren und gestalterisch weiterdenken kann.
Es ersetzt nicht den prüfenden Blick. Aber es macht den ersten Schritt deutlich leichter.
Wenn Schilder plötzlich lesbar werden


Noch ein Test: ein Wegweiser mit zwölf gelben Schildern, mehreren Zeilen pro Schild und kleinen absurden Ortsnamen wie „Wolpertinger-Rast“ oder „Verlorene Socke“. Das Modell hat die Beschriftungen nicht nur lesbar platziert, sondern auch den Humor der Aufgabe verstanden.
Gerade bei solchen Motiven merkt man den Fortschritt deutlich. Text in KI-Bildern war lange der Moment, in dem alles auseinanderfiel. Jetzt wird Text selbst zum Gestaltungselement: Überschriften, Labels, Hinweise, Schilder, Poster, Sprechblasen.
Der Hintergrund zeigt allerdings auch eine typische Schwäche: In Naturflächen entstehen teils sichtbare Muster und Artefakte. Für einen Stand-der-Dinge-Test ist genau das interessant, weil man nicht nur sieht, was schon gut klappt, sondern auch, wo GPT Image 2.0 noch nachbessern muss.
Eine weitere Einschränkung: Wenn du ChatGPT zu viel Freiheit lässt, wird es gerne textverliebt. Dann kommen noch eine Unterzeile, eine Infobox und drei Zusatzhinweise dazu. In einer frühen Ideenphase kann das spannend sein. Für ein klares Ergebnis solltest du den Text aber möglichst genau vorgeben.
Mockups und visuelle Konzepte werden einfacher
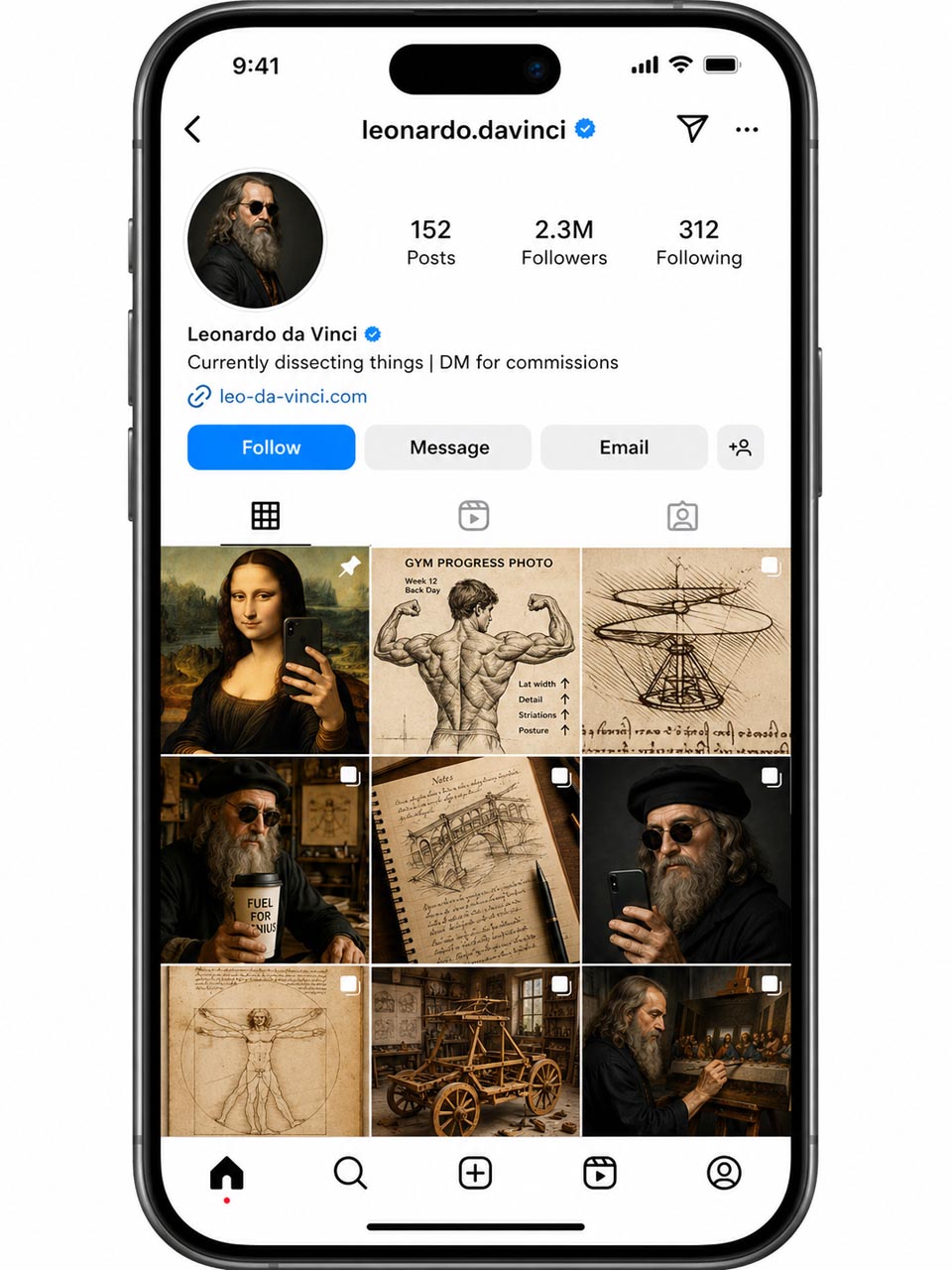
Sehr stark ist ChatGPT Images 2.0 auch bei Mockups. Ein Instagram-Profil von Leonardo da Vinci, inklusive Smartphone-Rahmen, Statusleiste, Follow-Button und Bilder-Grid? Funktioniert. Als visuelle Idee, als Aufmacher, als Social-Media-Gag oder als Konzeptbild ist das plötzlich schnell gemacht.
Für alle, die redaktionell, konzeptionell oder gestalterisch arbeiten, ist das ein riesiger Hebel. Du musst nicht immer sofort in Figma, Canva oder Photoshop einsteigen, nur um eine Idee sichtbar zu machen. Du kannst erst einmal testen: Trägt das Motiv? Versteht man den Witz? Ist die Bildidee stark genug?
Wenn ja, kann man sie sauber weiterbauen. Wenn nein, war es nur ein Prompt und ein paar Minuten Zeit.
Layouts: noch keine Druckdaten, aber starke Entwürfe



Bei den Rezeptkarten wollte ich bewusst wissen, wie weit sich ChatGPT auch auf ungewöhnliches Terrain einlassen kann. Der Auftrag lautete also nicht einfach nur „Mach mir ein Rezept“, sondern: Erfinde möglichst verrückte Kombinationen, die kulinarisch überraschen, dabei aber visuell ästhetisch wirken, mit spannenden Farben und einer stimmigen Gesamtanmutung.
So entstanden Vorschläge wie Matcha-Kiwi-Tacos, Sushi-Donuts mit Kirschen und Spargel oder eine Beetroot Piña No-Lada. Die Aufgabe war dann, daraus ansprechende Rezeptkarten mit nummerierten Zutaten und handschriftlich wirkender Anleitung zu gestalten.
Das Ergebnis war eher ein Designexperiment als ein realistischer Küchentipp, gestalterisch aber erstaunlich sauber. Die Karten hatten eine klare Hierarchie, schöne Farbzusammenstellungen und eine kleine, stimmige Designlogik. Genau solche Beispiele zeigen, dass ChatGPT nicht nur Inhalte bebildern kann, sondern auch bei ungewöhnlichen Ideen ein visuell schlüssiges Layout entwickelt.
Noch spannender wird es, wenn man das Ganze mit echten Inhalten füttert. Zum Beispiel mit Familienrezepten. Man könnte zum Beispiel die Oma einfach mündlich erzählen lassen, wie sie ihr Lieblingsgericht macht, inklusive der kleinen Tricks, die in keinem klassischen Rezept stehen: „Nicht zu früh umrühren“, „noch einen Schuss hiervon“, „das merkt man am Geruch“. ChatGPT kann daraus ein verständlich strukturiertes Rezept machen und anschließend eine optisch ansprechende Rezeptseite gestalten.
Das wäre für mich eine der schönsten Anwendungen: nicht nur neue Fantasie-Rezepte erfinden, sondern vorhandenes Wissen bewahren. Alltagsküche, Familiengeschichten, persönliche Kniffe, schön aufbereitet als kleine Rezeptkarte, Mini-Kochbuch oder Geschenk.
Besonders praktisch ist die Formatkontrolle. ChatGPT bietet zwar einige Standardformate zur Auswahl an, aber man kann auch sehr konkrete Maße vorgeben. Ich habe teilweise mit ungewöhnlichen Bildgrößen gearbeitet und die Maße direkt in Millimetern angegeben. Das Ergebnis passte erstaunlich genau.

Auch eine komplette Magazinanzeige lässt sich inzwischen aus einem einzigen Prompt als Entwurf erzeugen: Hauptbild, Textblöcke, Tippkasten, QR-Code, Call-to-Action, Schrifthierarchie. Nicht als fertige Druckdatei, aber als erstaunlich brauchbare Layoutidee.
Beim genaueren Hinsehen sieht man die Grenzen: Die Magazincover wirken nur ungefähr wie echte Ausgaben, kleine Details verschwimmen, manche Texte müsste man neu setzen. Für eine finale Anzeige hätte ich die echten Coverdateien im Layoutprogramm darübergelegt und alles sauber aufgebaut.
Genau darin liegt für mich der praktische Nutzen. KI liefert nicht zwingend das fertige Ergebnis, aber sie bringt dich viel schneller zu einer visuellen Richtung. Aus „Wie könnte die Anzeige aussehen?“ wird in wenigen Minuten ein konkreter Entwurf, den man prüfen, verbessern und professionell weiterverarbeiten kann.
Charaktere bleiben eher sie selbst



Wer regelmäßig mit Bild-KI arbeitet, kennt das alte Problem: Du erzeugst eine Figur, willst sie in einer anderen Szene zeigen, und plötzlich ist es jemand anderes. Andere Brille, anderes Gesicht, andere Ausstrahlung. Besonders bei wiederkehrenden Figuren ist das nervig.
Bei Dr. Buzz sieht man, wie weit die Modelle inzwischen gekommen sind. Einmal taucht er im Anzug in einem Pool, einmal fliegt er auf dem Skateboard durch eine Großstadt, einmal erscheint er in einem Scrapbook mit mehreren Stilvarianten. Natürlich muss man bei der Wiedererkennbarkeit immer noch genau hinschauen. Aber die Richtung stimmt: Locken, Bart, Brille, Krawatte, dieses leicht verschmitzte Professorenlächeln, vieles bleibt erstaunlich stabil.
OpenAI zeigt in den eigenen Beispielen ebenfalls mehrteilige Comics, Character Sheets, Infografiken, Layouts und Bildserien mit stärkerer Kontinuität über mehrere Szenen hinweg. Genau diese Fähigkeit macht das Modell für redaktionelle und serielle Arbeit interessant.
Denn sobald Figuren wiedererkennbar bleiben, entsteht nicht nur ein Einzelbild. Es entsteht eine visuelle Welt.
So bekommst du bessere Ergebnisse
Aus meinen Tests der letzten Wochen haben sich ein paar einfache Regeln ergeben.
Erstens: Wenn Text im Bild stehen soll, gib ihn möglichst genau vor. Je genauer Überschrift, Stichpunkte und Textmenge sind, desto besser wird das Ergebnis. Und wenn keine Zusatztexte ins Bild sollen, schreib das ausdrücklich dazu.
Zweitens: Beschreib das Layout. „Zentrale Speise in der Mitte, ringsherum nummerierte Zutaten, unten eine kurze handschriftliche Anleitung“ funktioniert besser als „Mach eine schöne Rezeptkarte“.
Drittens: Nutze das Gespräch. Du musst nicht alles in einen perfekten Prompt pressen. Du kannst erst mit ChatGPT über die Idee sprechen, Varianten sammeln, eine Richtung auswählen und dann daraus ein Bild erzeugen lassen.
Viertens: Bleib kritisch. Gerade weil die Ergebnisse so überzeugend aussehen, muss man genauer prüfen. Stimmen die Inhalte? Ist der Text korrekt? Ist das Layout wirklich sinnvoll oder nur hübsch? Gibt es Details, die bei genauerem Hinsehen auseinanderfallen?
Das neue Bildmodell ist stark. Aber es ist kein Autopilot für gute Gestaltung.
Wo Nano Banana weiterhin glänzt
Trotzdem ist Nano Banana nicht plötzlich überflüssig. Bei bestimmten Illustrationsstilen, feinen Stilübertragungen und manchen Bildbearbeitungen kann es weiterhin die bessere Wahl sein.
Bei Wimmelbildern ist das für mich besonders deutlich. Ich habe inzwischen einige davon erstellt, und hier gefällt mir der Stil von Nano Banana oft besser. Die Bilder wirken für meinen Geschmack lebendiger, detailreicher und näher an der Art von Wimmelbild-Ästhetik, die ich gesucht habe. Das heißt nicht, dass ChatGPT Images 2.0 das grundsätzlich nicht kann. Vielleicht lässt sich mit anderen Prompts noch mehr herausholen. Aber in meinen bisherigen Tests hatte Nano Banana in diesem Bereich die Nase vorn.
Mein aktuelles Bauchgefühl: ChatGPT Images 2.0 wird zum Layouter, Konzepter und visuellen Gesprächspartner. Nano Banana bleibt in vielen Fällen der starke Stilist und Bildbearbeiter.
Und was machen jetzt die Grafiker?
Diese Frage musste kommen. Kaum ein starkes Bild-KI-Update erscheint, ohne dass irgendwo jemand schreibt: „Designer sind erledigt.“ Und ja, ich verstehe, warum viele Grafikerinnen und Grafiker bei solchen Beispielen erst einmal schlucken. Wenn plötzlich auch Menschen ohne Designstudium Anzeigen, Mockups oder Infografiken erzeugen können, fühlt sich das nach Kontrollverlust an.
Ich sehe es trotzdem anders. Für mich ist diese Entwicklung nicht das Ende von Gestaltung, sondern ein großer Schritt in Richtung Erleichterung. Bild-KI nimmt uns viele mühsame Zwischenschritte ab. Sie macht Ideen schneller sichtbar, liefert Varianten, hilft beim Sortieren und bringt Menschen überhaupt erst in die Lage, visuell zu denken, auch wenn sie keine Profis sind.
Natürlich wird das den Markt verändern. Standard-Flyer, schnelle Social-Media-Grafiken, einfache Mockups und Routine-Infografiken werden künftig schneller und günstiger entstehen. Das kann für manche Bereiche unbequem werden. Aber gutes Design beginnt für mich nicht dort, wo etwas hübsch aussieht, sondern dort, wo es etwas transportiert.
Gutes Design bedeutet: auswählen, gewichten, reduzieren, entscheiden. Erkennen, wann etwas zu glatt ist. Prüfen, ob ein Bild wirklich zur Marke, zum Thema und zur Botschaft passt. Und aus vielen guten Vorschlägen den einen auswählen, der nicht nur schön aussieht, sondern etwas Eigenes hat.
Genau deshalb werden Grafikerinnen und Grafiker nicht automatisch überflüssig. Ihre Rolle verschiebt sich. Weniger Fleißarbeit, mehr Konzept. Weniger „Kannst du mal schnell zehn Varianten bauen?“, mehr Auswahl, Feinschliff und Haltung. Wer KI klug einsetzt, wird schneller und freier. Wer sie blind einsetzt, produziert vielleicht mehr, aber nicht unbedingt besser.
Und wer denkt, dass schöne Bilder automatisch gutes Design sind, hat sich vermutlich schon vor ChatGPT geirrt.
Was noch fehlt
Einen Wunsch habe ich trotzdem. Wenn KI-Bildtools irgendwann saubere Vektorgrafiken ausgeben und generierten Text als editierbare Schrift liefern, wird es noch einmal richtig interessant.
Stell dir vor, du erzeugst eine Infografik, klickst auf einen Text und kannst Schriftart, Größe oder einzelne Wörter ändern. Oder du wandelst eine Illustration direkt in eine Vektordatei um, die du in Illustrator weiterbearbeitest. Dann wären KI-Bilder nicht mehr nur Vorschauen, Moodboards oder Inspirationsmaterial. Dann würden sie zu echten Bausteinen im professionellen Workflow.
Noch sind wir nicht dort. Aber mit ChatGPT Images 2.0 fühlt es sich zum ersten Mal so an, als wäre dieser Schritt nicht mehr weit weg.
Für mich ist das keine Bedrohung von Gestaltung, sondern eine Verschiebung des kreativen Prozesses. Schneller vom Gedanken zum Entwurf. Schneller von der vagen Idee zu einer sichtbaren Richtung. Weniger technische Hürde, mehr Raum für Auswahl, Feingefühl und Weiterentwicklung.
Und genau deshalb finde ich diesen Fortschritt nicht gruselig, sondern ziemlich aufregend.
- Bildmodell mit eingebautem Denkschritt vor der Bildgenerierung
- Texte im Bild sind endlich zuverlässig: Plakate, Schilder, Infografiken funktionieren
- Charakterkonsistenz über mehrere Bilder, Panels und Stile hinweg
- ChatGPT zieht Kontext aus dem laufenden Gespräch und erkennt Themen, an denen du gerade arbeitest
- Komplette Layouts wie Rezeptkarten, Anzeigen oder Mockups aus einem einzigen Prompt


11. Juni 2026
Genießt die Spiele!Deine WM braucht ein KI-Upgrade
30. Mai 2026
Eigene Skills erstellenSo baust du deinen ersten KI-Helfer mit Claude
18. Mai 2026
EU AI Act verschoben?Neue Fristen, neue Verbote – der aktuelle Stand
17. Mai 2026
Schöne neue KI-Welt?Utopie oder Chaos – was erwartet uns?
18. April 2026
KI-Agent OpenClawWoher bekommen, wie installieren, was absichern?